While CMS does not suggest it, if you wanted to use only those tokens that are trained by your samples, it is possible to do so. This does mean that you will clear the default token database provided by CMS, and that you will have to capture your own samples.
To reset the token database and only populate it with your message samples, you will first need to completely clear the PraetorWordList table in the PraetorClassify SQL database. Call CMS Support for instructions on how to empty this table of the default entries.
In the meantime, before the default token database is cleared, you will need to capture message samples for use in training. In this situation preliminary classification relies entirely on the default rules to identify spam from good messages.
The process is:
Capturing message samples after switching to BASIC filtering mode.
Verify each message has been classified correctly as spam or non-spam.
Shutdown Praetor by stopping the IIS.
Clear the default token database entries per CMS instructions.
Train the Bayesian filter using these captured samples.
Re-start IIS.
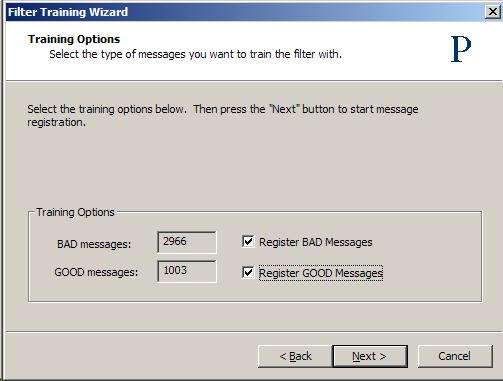
To facilitate the accumulation of spam and ham messages for initial bulk training, Praetor provides several novel training options for capturing samples as seen below on the Train tab page of the configuration window.
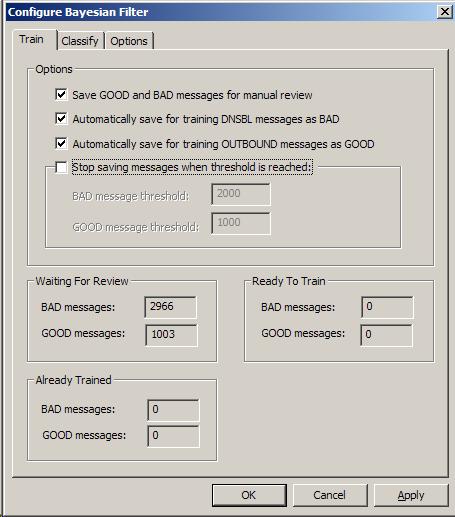
The only administrator control on this training page is within the Options group box. The other remaining group boxes show information about how many messages are in the various states. Here are the options that you may set:
Using the default rule-based filters to make
the initial classification, Praetor will save a copy of those messages
that were quarantined as spam or accepted as ham. This
will allow you to review each type for any incorrect classification, removing
them as needed. Such
messages will be placed on the  list of the
list of the  and
and  nodes.
nodes.
This selection automatically queues for training
as BAD (spam) any message that originates from a known spam mail server
whose IP address is on the DNS blacklist.
While it is possible that GOOD email might be incorrectly classified if
your trading partner has a blacklisted mailserver, this should happen
infrequently if at all. If
you detect this in the auto-queued BAD list, you can manually mark the
message as Queued for GOOD. Be
sure to add their IP address into the DNSBL bypass
IP list.
This selection will automatically mark messages from local users in your domain that go out to the Internet as ham.
Warning:
|
The possibility of BAD outbound messages does exist and so it could bias the GOOD frequency table. This could happen if you have a machine in your network that is infected with a mass-mailing worm that spews outbound email to all the people in the local contact list. Another possibility is that you perform broadcasts to customers that is spam-like. In either of these cases, don't enable this option. Doing so and training upon those messages will likely make your token database 'dirty' and decrease its effectiveness. |
This selection will cause Praetor to capture
a specified number of sample inbound and outbound messages using the existing
methods (default Bayesian tables and rules) to classify as GOOD or BAD
for review.
CMS suggests that you set a value of at least 1000 messages. Depending
on your user population this may give you sufficient diversity of messages
indicative of the business correspondence for your site. While
a larger sample size tends to show greater diversity and the Bayesian
filtering will become more accurate in its discrimination between spam
versus ham, keep in mind that it will take you longer to verify that the
classification is correct before you perform the training. Also,
this larger sample will take longer to process. With
a smaller sample size, you can at least get the initial training done
so that you can quickly start to see the benefits of the Bayesian filtering.
These Praetor options are convenient ways to accumulate trainable messages. The use of the DNSBL and outgoing samples are especially convenient since these captured messages are not likely to need your review.
For initial bulk training purposes CMS recommends that you check all the above four options, perhaps adjusting the quantity for how many messages to save for training. Click here for a discussion of periodic incremental training.
![]() Note:
Note:
|
If you have placed your Praetor G2 behind
an existing Praetor v1.5, then G2 may not be getting any messages to quarantine
since v1.5 may have already done so. In
this situation it is possible to copy those message samples from the v1.5
QUAR folder and import them into the G2 |
Other group boxes on this page are:
|
show messages that were captured by rule filters that require review to insure they were correctly classified as GOOD or BAD |
|
are those messages you have already reviewed and those automatically captured by DNSBL (BAD) or by outgoing from your own local users (GOOD) |
|
are those messages that have been analyzed and the frequency database has been updated with what tokens were found |
Once messages have been captured, the initial training process consists of two steps: review and train.
|
1. |
Review captured messagesPeriodically check on the captured BAD messages
by selecting the Right-mouse click on a selected message and you will be presented with the following possible actions.
Choosing either action to train will cause immediate analysis and adjust
the appropriate frequency table with the tokens seen. If
this action is selected, the message entry will move to the Please note that training on-the-fly in this manner may take some time and will impact Praetor mail reception and filtering. For initial bulk training CMS does not recommend you to perform training; instead you should choose the action to Queue the message or simply Delete it from the list. When you choose to Queue (recommended for initial bulk training), this
will simply mark that message for later training using the training
wizard. This
choice will also move the message entry to the appropriate
In case the message summary that is visible from the list is insufficient and you are unable to determine whether it is really GOOD or BAD based on the sender address or subject matter, then you can open the selected message by double-clicking on the entry. This will present you with full message details showing the message header and its contents. The same actions are now available as buttons in the message window that appears.
In a similar manner, periodically check on the captured GOOD messages
by selecting the
| ||
|
2. |
Invoke Training WizardOnce you have the reviewed the messages that were in the
Pressing
Note the numbers shown for training are those found in the
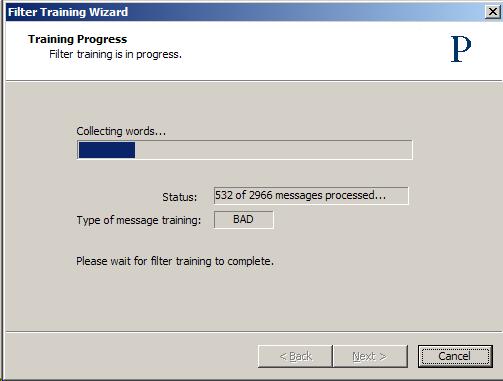
The training process consists of processing each message to break it down into its component tokens and accumulating them.
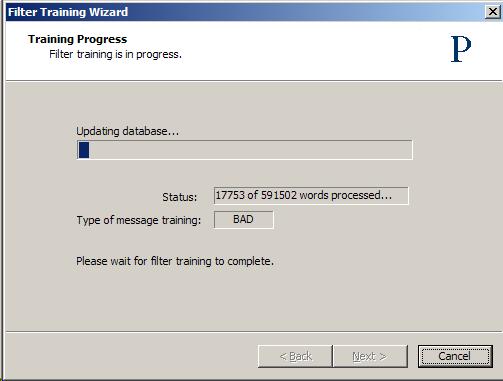
After this collection is done, the token database is updated with the addition of new tokens that are found in the training samples.
Depending on how many messages you train, how many tokens are found, and how busy the Praetor machine is, the training process may take some time and a significant amount of CPU resources. Therefore it is a good idea to perform this training during a period when the machine is not busy. The counter in the above display is only updated periodically so that resources are not wasted for display. Once the initial bulk training is completed, all the messages once listed
as To begin using the Bayesian filter to classify your messages, you will need to make the setting change from training on this page.
|
 node.
node.  node.
node.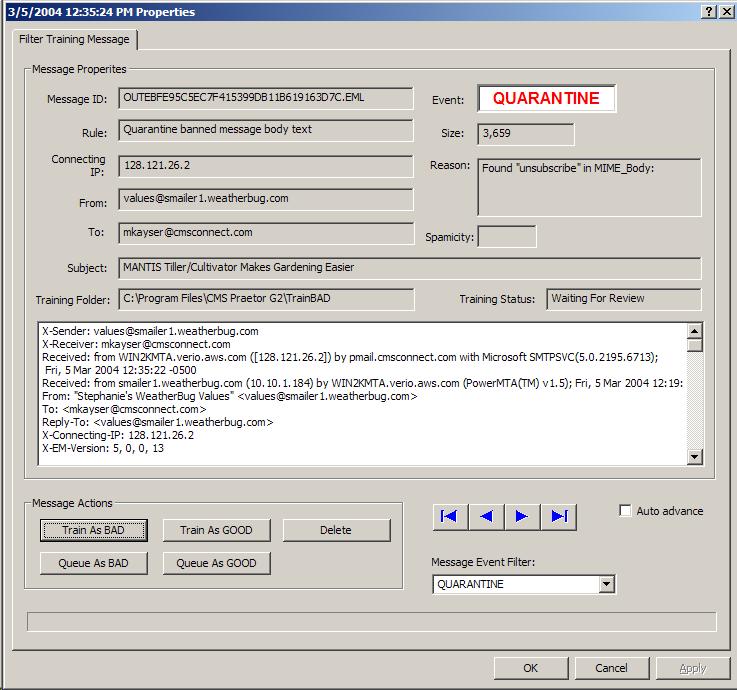

 displays the review window allowing you to select
which class you want to train -- GOOD, BAD, or both.
displays the review window allowing you to select
which class you want to train -- GOOD, BAD, or both.