|
You do not have to constantly train the Bayesian filter. Incremental training is suggested periodically and only on the errors:
Doing this will improve the spam detection accuracy and reduce falsely classified good messages that the Bayesian filter considers as spam (false positives). When you first install and use Praetor, if you find the spam detection rate satisfactory and false positives sufficiently low, you will not need to perform any training whatsoever. If you do any training, keep in mind that:
More training tips can be found in this FAQ. The following screen appears with the Classify tab when you have selected the BASIC pre-configured filters on the Configure Spam Filters page. The Classify tab will not appear if you are using the default ADVANCED filters. |
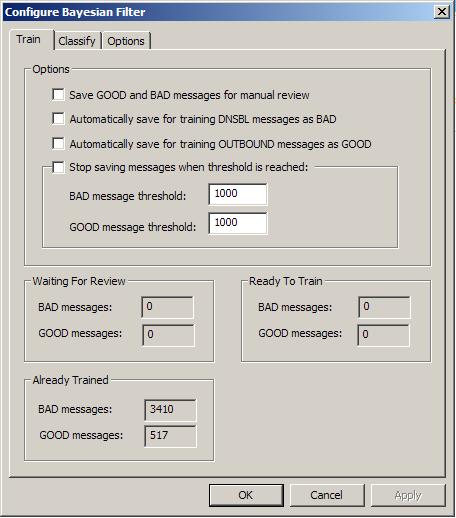
The optional checkboxes shown above for automatically saving training samples were designed to capture samples if you were to clear the default Bayesian token database supplied with your Praetor installation. CMS does not recommend using these checkboxes for incremental training purposes. Incremental training should only be performed only on Bayesian classification errors: non-spam that are quarantined and spam that are rated as unsure.
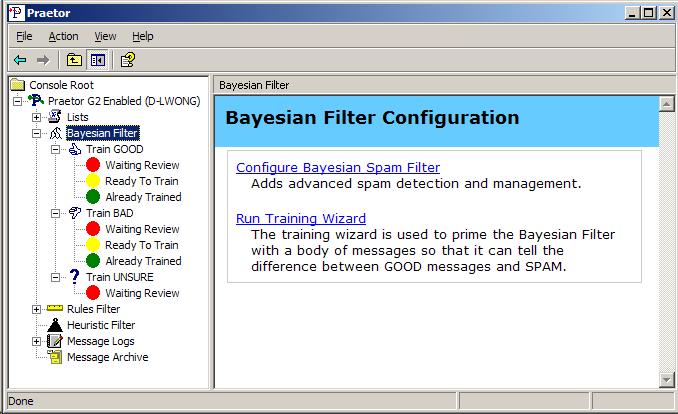
As supplied, Praetor includes a default Bayesian token database obtained from training on several thousand samples, which you can see in the Already Trained groupbox in the above screen image. Thus initial training is not a necessary step to begin using Bayesian filtering. CMS periodically tests this default token database by submitting spam samples that would normally be rejected by DNS Blacklists, and we find that the Bayesian filter will catch >90% of these received spam samples.
Nevertheless our default token database may still cause the Bayesian filter to allow a few messages to get improperly classified. Especially important are the good messages that get quarantined (called "false positives") and spam that is accepted because it was rated as unsure (called "false negatives") . By periodically retraining on these Bayesian classification errors you can get the filter to be even more accurate for both good and bad messages, increasing the spam detection rate while lowering the false positives and false negatives.
This section discusses:
Training the good messages classified as spam by the Bayesian filter
Training on errors caught by Bayesian filter as unsure, heuristics, etc.
If for some special reason you want to perform initial training from a completely blank token database, then it would be best if you first contact CMS to discuss this need. This would be an extremely unusual situation that you need to start from a blank database. You can read about the process by clicking here.
For more tips on training your Bayesian filter, view this FAQ.
The default token database already includes far many more spam than good message samples so CMS recommends that you focus your effort on training Praetor with the following types of messages.
False positives which are good messages that get quarantined as spam either by the Bayesian or heuristic filters.
False negatives which are spam messages that are not caught because the Bayesian filter classified them as unsure.
Keep in mind that, if those false positives are messages coming from listservers (e.g. airline promotions, newsletters, joke-of-the-day, etc.) you should just add the listserver addresses to the approved listserver list and avoid Bayesian classification altogether. Messages from listservers tend to have characteristics that are spam-like so training these as good message samples would only 'dirty' the token database and make the Bayesian filter less accurate. Thus, it is a bad idea to train messages from listservers.
![]() Note:
Note:
|
Some listserver addresses may contain variable information to the left of the @-sign. This tab page is only visible if you have selected the BASIC pre-configured filters on the Configure Spam Filters page. It does not apply to the ADVANCED selection since you have full control via the configurable rules. |
The two main message types listed above are trained in slightly different ways by the administrator because of the difference in how frequently they are captured. In both cases, the administrator must verify the improper classification by the Bayesian filter and queue for training as spam or non-spam. Users do not have this opportunity because of the risk in poisoning the token database that would render it less useful in properly discriminating spam.
Praetor provides a novel method for training messages that the Bayesian filter improperly classified as spam — use those messages that have been reviewed and then released by the administrator(s). This is performed by using the Praetor administrator console selectively reviewing the quarantined messages listed in the Current Events view of the Message Logs, a facility we call the Log Viewer.
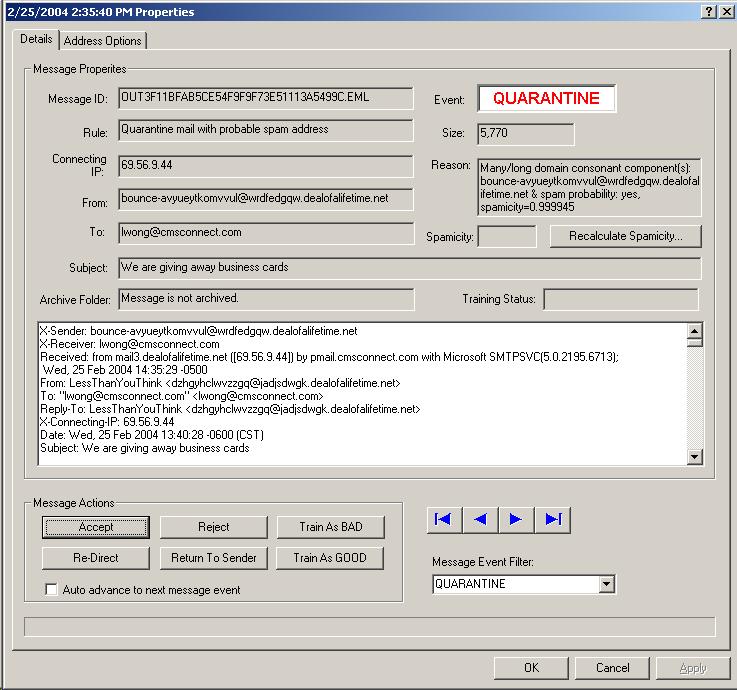
When the message details
are shown and you have determined this is a good message, press  to update the token database with this message sample before
pressing
to update the token database with this message sample before
pressing  to release the message from quarantine.
to release the message from quarantine.
Praetor can be configured to save all messages classified as UNSURE by the Bayesian filter. There are two distinctly different methods to configure this, one for the default ADVANCED filtering mode and another for the BASIC mode. See how this configuration is done here.
You will find the captured
UNSURE messages listed in the Praetor administration program when selecting
the  node for
node for  . It
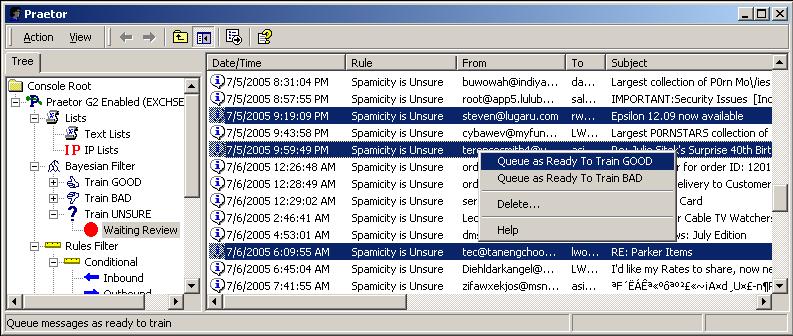
is likely that you can quickly determine if a message is spam simply by
looking at the From or Subject columns. Once
you have verified the proper classification for a group of messages, highlight
the group and right-mouse click to select to queue for training either
as GOOD (non-spam) or BAD (spam).
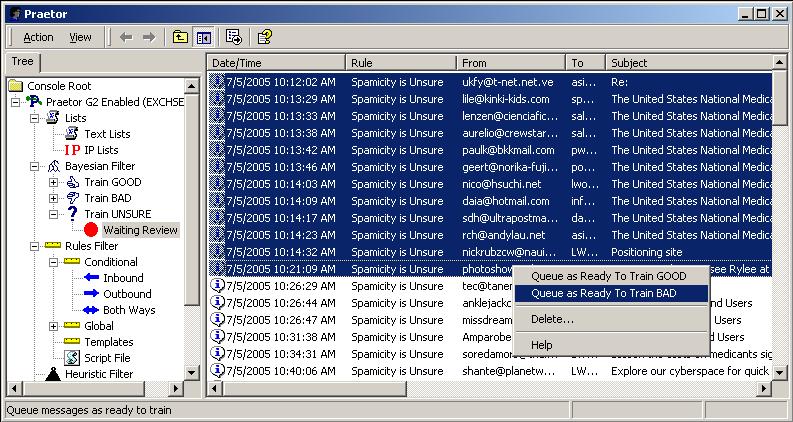
. It
is likely that you can quickly determine if a message is spam simply by
looking at the From or Subject columns. Once
you have verified the proper classification for a group of messages, highlight
the group and right-mouse click to select to queue for training either
as GOOD (non-spam) or BAD (spam).
Here are some suggestions whether or not to train for other rules that may have caught messages listed as UNSURE. Note that the name may be slightly differently than those listed, but they convey the same idea.
|
Rule capturing the unsure message |
Train |
Don't Train |
|
Heuristics |
X |
|
|
DNS Blacklist |
|
X |
|
Spamicity is UNSURE |
X |
|
|
Spam-related rules |
X |
|
|
Reverse NDR |
|
X |
|
Approved domains, senders, listservers |
|
X |
|
Other non-spam related rules |
|
X |
When you choose to queue
for training, this will simply mark that message for later training using
the training wizard. As
a result, this choice will move the message entry from the node of to the to the  node for
either
node for
either  or
or  as appropriate.
as appropriate.
Next you will run the training wizard so that
these queued messages are analyzed and the Bayesian token
database is updated.

Pressing  displays the review window allowing you to select
which class you want to train -- GOOD, BAD, or both.
displays the review window allowing you to select
which class you want to train -- GOOD, BAD, or both.
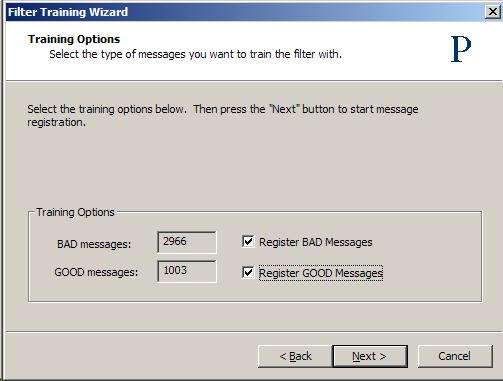
Note the numbers shown for training are those found in the state for both GOOD and BAD. Press
to begin the training.
![]() Warning:
Warning:
|
CMS does not recommend performing bulk training during the business day. The reason this is unwise is that the number of simultaneous accesses to the MSDE SQL Server will likely exceed the limit of 8 and this will cause its workload governor to get engaged. This governor will slow both Bayesian classification of incoming messages and the training. |
The training process consists of processing each message to break it down into its component tokens and accumulating them.
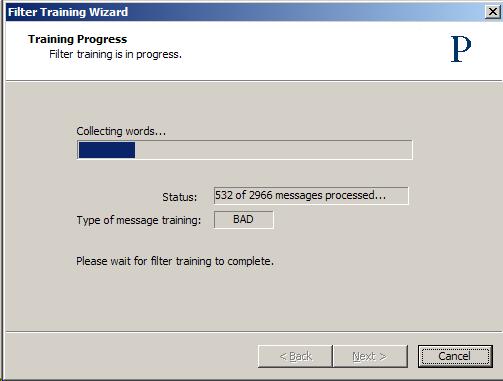
After this collection is done, the token database is updated with the addition of new tokens that are found in the training samples.
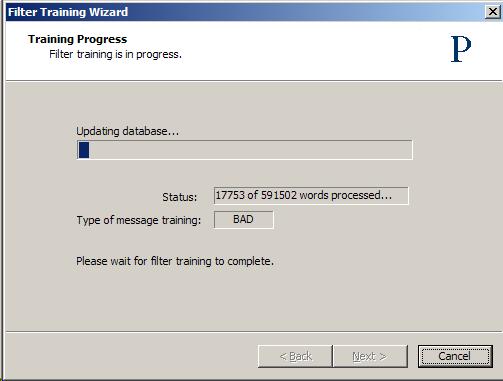
Depending on how many messages you train, how many tokens are found, and how busy the Praetor machine is, the training process may take some time and a significant amount of CPU resources. Therefore it is a good idea to perform this training during a period when the machine is not busy.
The counter in the above display is only updated periodically so that resources are not wasted for display.
Once the initial bulk training is completed, all the messages once listed
as will now be found in the  archive list
for the GOOD and BAD nodes. You
can always check how many messages have been trained thus far by viewing
the Train tab page of the Bayesian
configuration.
archive list
for the GOOD and BAD nodes. You
can always check how many messages have been trained thus far by viewing
the Train tab page of the Bayesian
configuration.
To begin using the Bayesian filter to classify your messages, you will need to make the setting change from training on this page.
![]() Note:
Note:
|
Once training has been performed, the message samples will
remain in the TrainBAD or TrainGOOD physical folders on the disk indefinitely.
The reason
for leaving these message samples is to allow you to re-use them in future
initial training after resetting (emptying) the token database. If
you want, you may delete these files by using the administration program
and highlighting all entries in |