|
INTRODUCTION |
|
Praetor's Bayesian filter can be trained to achieve more accurate
filtering results, reducing "False Positives" and "False
Negatives".
|
 |
FALSE POSITIVES
Non-spam, quarantined email |
|
|
FALSE NEGATIVES
Spam email reaching a user's inbox |
The goal is to obtain an acceptable balance between these classification errors.
|
|
 An Achievable False Positive Rate
An Achievable False Positive Rate
A false positive rate of 1 in 2000 messages (0.05%)
or lower is possible. CMS
studies have shown that Praetor achieves a false
positive rate much lower than 0.05%
The user population size directly affects false
positive rates. A larger population has a more
wide-ranging message content than a smaller one and
possibly leads to conflicting Bayesian tokens.
For example, a "joke-of-the-day" email may be
popular with some but considered spam by others.
Bayesian training on this as spam and non-spam
samples will dilute statistics for tokens in those
messages. |
|
An
Achievable False Negative Rate
A reasonable
false negative rate is less than 5% of all inbound messages.
A false
negative rate is not as easy to see as a false positive rate.
It is determined from the messages whose "spamicity" is
classified as "unsure" by the Bayesian filter and delivered.
A majority of
these "unsure" messages will be spam. To a lesser extent, there
will also be spam with low spamicity values.
|
|
Counter
Opposing Forces
In discussing
the false positive/negative rate,
realize that these represent counter-opposing forces.
Trying
to get an extremely low false positive
rate will typically cause more false negatives.
Likewise,
attempting to achieve a lower percentage of spam reaching a
user's inbox will raise the false positive rate.
A Praetor
site can determine their false positive rate by using the
Log Analyzer
and viewing the "Special
Traffic Summary Report".
|
Praetor's Bayesian filtering can
easily stop 95% of all spam
with much less than 0.05% for the false
positive rate.
|
|
|
|
|
|
WHAT TO "DO" DURING PRAETOR BAYESIAN TRAINING |
Be
Sensible in Training
To get good
performance from Praetor's Bayesian filter does not require
training on excessive numbers of emails. CMS studies have
determined that starting with Praetor's default token database
and training selectively (as described below) over short periods
of up to one week will yield better
results.
Accumulating
tens of thousands of emails for training may even be detrimental
to Bayesian filtering efficiency:
|
|
|
Good and
bad counts on large numbers of email messages tend to
equalize and won't become significant in
the overall spamicity calculation. |
|
|
|
More tokens require more
memory to cache and take longer to initially populate the cache. |
|
|
|
More tokens cause more
floating point calculations, consuming CPU resources and slowing
down the filtering. |
|
|
Add
Entries To Address And Domain Whitelists
If some users request to always accept
messages originating from a particular address or domain, then add these to the
"Approved Senders" or "Approved Domains" list.
WARNING: POTENTIAL OPENING FOR VIRUSES
Email-borne infections usually forge
the sender address with something it found in the local address book of an
infected machine.
There is a small risk that such an
address may be on the whitelist.
This risk
is eliminated by Praetor as long as the default rule order
is maintained. This puts the rules for attachment tests
before the rules for the whitelists. |
|
Train
Periodically, Only When Needed
The administrator can use the Praetor
Log Analyzer
to determine if more training is needed.
Viewing the "Special
Traffic Summary Report" can determine if the number of
false positives is too high.
False negatives most likely are messages with "unsure" spamicity and
will be difficult to detect. Many messages of "unsure" spamicity
are valid mail. A false negative problem could go unnoticed until the user
population complains of receiving too much spam.
|
|
Add
Listserver Addresses
Listservers sending newsletters, discount notices, etc.
tend to have spam-like characteristics and it is good
practice to simply add their addresses to the "Approved
Listserver Address" list.
To place an address into the list when reviewing details of the message, select
the
Address Options tab and check the box for the
desired list. This bypasses the Bayesian filter.
Some listservers use a sending address where the item left of the "@" character
is auto-generated. In these cases, it is not sufficient to use the
"Approved Listserver Address" list. An entry must be added to the
"Approved Domains" list.
|
NOTE: CMS experience has found that
instead of unsubscribing, some use
Praetor to filter listserver messages.
Administrators should not
comply with user requests to train on such messages as spam. This
may cause problems for others who want to continue their
subscription.
Simply ask those who don't want to receive such messages
to unsubscribe from the listserver. |
|
|
|
Train
Only On Errors
The Bayesian filter is best
trained with message samples on
which it has made classification errors.
|
|
|
Good messages quarantined due
to spamicity exceeding a high threshold value (Praetor default
is 0.60). |
|
|
|
Good messages rated as
unsure because their spamicity is between the low and high threshold
values (Praetor default from 0.30 to 0.60). |
|
|
|
Spam messages rated as unsure. |
A good message, wrongly quarantined,
can be approved by an administrator using the Praetor Administration Program.
It is then automatically queued for Bayesian training as a good sample.
For email deemed as
unsure by Praetor and delivered to the intended recipients,
an administrator must set a rule to archive a copy of these
messages into the "TrainUNSURE Waiting Review" table.
|
|
|
|
WHAT TO "NOT DO" DURING PRAETOR BAYESIAN TRAINING |
Don't
Train Spam Already Classified As "High Spamicity"
If Praetor's spam threshold is at 0.60 (the default) and there
are spam messages with spamicity of 0.61 or higher,
it is pointless
to train on these messages
Whether the computed spamicity
is between 0.61 to 1.00 in the future, the message is still quarantined simply because
it exceeds your spam threshold value.
|
Don't
Train non-Spam Already Classified As "Low Spamicity"
If Praetor's non-spam threshold is at 0.30
(the default) and good messages have a spamicity less than this level,
it is pointless
to train on these messages to get the spamicity computed even lower.
In the future, similar non-spam messages
resulting in a spamicity between 0.00 to
0.29, will still be treated as good messages and accepted because their
spamicity is below the low threshold value.
|
|
|
SAVING "UNSURE" MESSAGES FOR TRAINING |
|
In
ADVANCED filtering mode configure the additional rule
action to save the accepted message into the TrainUNSURE folder by performing
these steps in the Praetor administration program: |
|
Step 1 |
In the Inbound rules list, highlight
the "Spamicity is unsure" rule and double-click to open its properties. |
|
Step 2 |
View the tab for the "Actions".
Select "save message as
training type in
training folder".
|
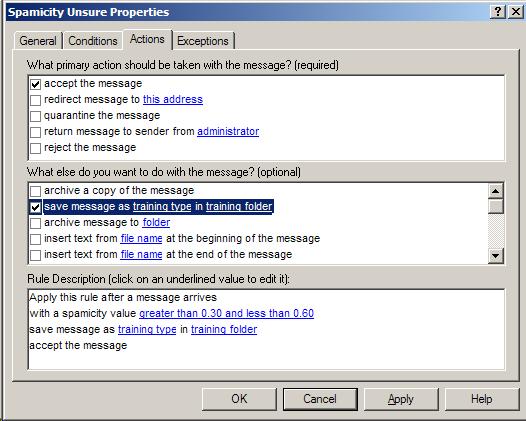 |
|
Step 3 |
In the "Rule Description" window
of the "Actions" tab, click the "training type".
Select "Save message as Train UNSURE".
|
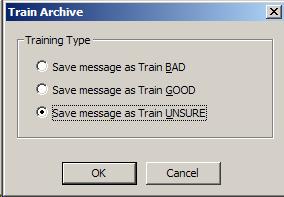 |
|
Step 4 |
Staying in the "Rule Description" window, click
on the "Training Folders".
Do not change the
default selection "Waiting for Review".
|
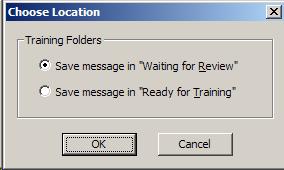 |
|
Step 5 |
A modified "Rule Description" should
reflect these changes.
Click
"Apply"
to complete the rule modification.
To put the
modifications into effect save the rule set. |
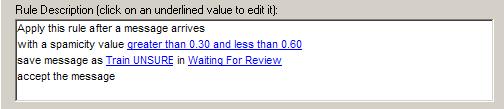 |
|
Step 6 |
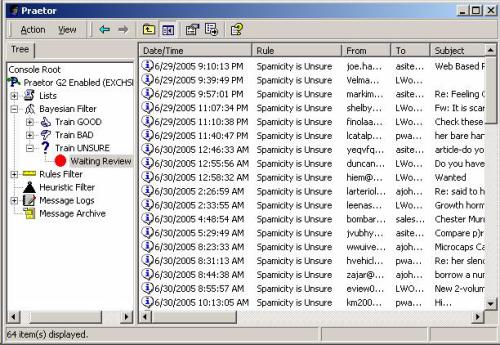
Messages held in "Train UNSURE" under the "Waiting Review" node, are
queued for review. These messages can be designated as good or bad
samples for Bayesian training.
|
 |
|


